Progressive Generation of Extra-Long Text
January 01, 1970
Abstract
Large-scale language models pretrained on massive corpora of text, such as GPT-2, are powerful open-domain text generators. However, as our systematic examination reveals, it is still challenging for such models to generate coherent long passages of text (\(>\)1000 tokens), especially when the models are fine-tuned to the target domain on a small corpus. To overcome the limitation, we propose a simple but effective method of generating text in a progressive manner, inspired by generating images from low to high resolution. Our method first produces domain-specific content keywords and then progressively refines them into complete passages in multiple stages. The simple design allows our approach to take advantage of pretrained language models at each stage and effectively adapt to any target domain given only a small set of examples. We conduct a comprehensive empirical study with a broad set of evaluation metrics, and show that our approach significantly improves upon the fine-tuned GPT-2 in terms of domain-specific quality and sample efficiency. The coarse-to-fine nature of progressive generation also allows for a higher degree of control over the generated content.
1 Introduction↩︎
Large-scale pretrained language models (LMs) have enabled groundbreaking performance across a wide range of tasks peters2018deep?, devlin2018bert?, radford2018improving?, wang2018glue? and have become an essential component of the modern natural language processing toolkit. OpenAI’s GPT-2 radford2019language?, in particular, emerged as an impressive open-ended text generator capable of producing surprisingly fluent text.


Figure 1: Results of large-scale LMs (GPT-2 and BART) fine-tuned on 10K stories. Left: Coherence of text evaluated by BERT next sentence prediction (NSP) score, where x-axis is the position of the evaluated sentences in the passage. There is a significant gap in coherence between text by human and text by large-scale LMs. Our proposed ProGeT instead generates more coherent samples close to human text. Right: Example text generated by GPT-2. The text is not coherent by talking about irrelevant topics in different parts. The full example is shown in the appendix..
Typically, models such as GPT-2 or BERT devlin2018bert? are pretrained on large corpora of unlabeled text once, and then fine-tuned on a small amount of supervised data for downstream tasks, such as summarization, translation, and storytelling mao2019improving?, ziegler2019encoder?, see2019massively?. Previous work has mostly focused on the short text regime, where the target text ranges between tens to low hundreds of tokens. For example, holtzman2019curious?, see2019massively? studied and improved the quality of GPT-2 generations with a maximum length of 200 and 150, respectively. It remains unclear how the powerful text generators perform for generating coherent long passages of text (e.g., 1000s of tokens).
In this work, we examine fine-tuning of large-scale LMs for domain-specific generation of long text. We find that samples produced by GPT-2 fine-tuned on small domain-specific corpora exhibit various imperfections, including excessive repetitiveness and incoherence between sentences far apart. Figure 1, right panel, measures the coherence of text generated by the fine-tuned GPT-2 w.r.t the BERT next sentence prediction devlin2018bert? score. As the figure shows, GPT-2 models (regardless of the model size) exhibit a significant gap in the score compared with human text, hence falling short in generating coherent text. An example generation by GPT-2 is shown in the right panel of the figure.
[hzt: planning then generation] We hypothesize that the problem is caused by the sequential generation order of the LM, which makes global planning of the content of the passage difficult, especially when the generated text is long and contains thousands of words.
To overcome this limitation, inspired by progressive image generation karras2017progressive?, park2019semantic?, we introduce a new method for Progressive Generation of Text (ProGeT). We observe that generation of some words (e.g., stop words) does not require many contexts, while other words are decisive and have long-term impact on the whole content of the passage. Motivated by this observation, our approach first produces a sequence of most informative words, then progressively refines the sequence by adding finer-grained details in multiple stages, until completing a full passage. The generation at each stage is conditioning on the output of the preceding stage which provides anchors and steers the current generation (Figure 2).
Importantly, the simple design of progressive generation allows us to still make use of pretrained LMs. In this work, we use GPT-2radford2019language? or BART lewis2019bart? for generation at each stage, though one can also plug in other off-the-shelf LMs. The LMs at different stages are easily fine-tuned to accommodate a target domain using independently constructed data. Intuitively, each LM is addressing a sub-task of mapping a sequence to a finer-resolution one (or mapping the condition to a short coarse-grained sequence at the first stage), which is much simpler than the overall task of mapping from conditions to full passages of text. As seen from Figure 1, ProGeT can generate more much coherent text compared with GPT-2 and nearly match human text in terms of the BERT-NSP score.
The coarse-to-fine progressive generation conceptually presents a non-monotonic (non-left-to-right) process. Compared to many of the recent non-monotonic or non-autoregressive generation methods fan2019strategies?, welleck2019non?, gu2019insertion?, stern2019insertion?, chan2019kermit? with customized neural architectures or dedicated inference procedures, our approach is simple and permits seamless use of powerful pretrained LMs. The new non-monotonic use of pretrained LMs enables long text generation in any target domain.
Through an extensive empirical evaluation on the CNN News hermann2015teaching? and WritingPrompts fan2018hierarchical? corpora, we demonstrate that ProGeT is able to produce diverse text passages of higher quality than fine-tuned GPT-2 and BART models in the target domains, as measured by a wide range of metrics. ProGeT is also much more data efficient when adapting to the target domains.
[other 2-step papers]
[GPT-3]
[other papers with "Long Text" in titles]
2 Related Work↩︎
The idea of planning-then-generation is not new, and has been studied in early text generation systems for specific tasks. For example, conventional data-to-text generation systems reiter1997building? separate content planning and surface realization. Recent neural approaches have also adopted similar two-step generation strategy for data-to-text moryossef2019step?, puduppully2019data?, storytelling fan2019strategies?, yao2019plan?, machine translation ford2018importance?, and others hua2019sentence?, yao2017towards?. In a similar spirit, many efforts have been made in developing non-monotonic or non-autoregressive generation models that differ from the restricted left-to-right generation in conventional LMs welleck2019non?, gu2019insertion?, stern2019insertion?, chan2019kermit?, zhang2020pointer?. Our work differs in several dimensions: (1) differing from the previous work where the generated text ranges between tens to low hundreds of tokens, we study the generation of long text consisting of 1000 or more tokens; (2) our progressive process can be seen as a generalization of the two-step planning-and-generation approaches by allowing arbitrary multiple intermediate stages. We propose a simple yet effective way for designing the multiple stages that can be trained independently in parallel; (3) Compared to the previous work that usually involves customized model architectures or dedicated inference processes, our approach instead provides a framework for plugging in any common pretrained LMs, and thus combines the power of large-scale pretrained LMs with non-monotonic generation to enable coherent long text generation.
There has been a lot of recent interest in using large-scale pretrained LMs for improving domain-specific generation mao2019improving?, ziegler2019encoder?, see2019massively?, in which generated text is typically much shorter than the samples considered in this work. Few recent work extended the transformer architecture vaswani2017attention? for generating long text, e.g., liu2018generating? used a hybrid retrieval-generation architecture for producing long summaries; dai2019transformer? showed long text samples qualitatively. Our work systematically examines the pretrained LMs in generating long domain-specific text, and proposes a new approach that empowers pretrained LMs for producing samples of significantly higher-quality.
3 Background↩︎
We start by reviewing the problem of text generation including language modeling and sequence-to-sequence (seq2seq) methods that serve as building blocks of our progressive generation approach. We also introduce the notations used in the rest of the paper.
Text generation and language models. Our discussion centers around methods for text generation using models that can produce outputs of the form \(\yv := [y_1, y_2, \dots, y_T]\), where each \(y_i\) is a token of language (a word or a sub-word). The output sequences are generated either conditionally on another sequence of tokens, \(\xv := [x_1, x_2, \dots x_S]\) (, generations of a story given a prompt), or unconditionally (in which case we assume \(\xv \equiv \varnothing\) while keeping the same notation). To generate sequences, we need to represent conditional (or unconditional) probability distributions of the form \(\prob[\theta]{\yv \mid \xv}\) with learned \(\theta\), typically factorized into a product of conditional distributions over tokens: \[\label{eq:sequence-model} \prob[\theta]{\yv \mid \xv} := \prod_{t}\prob[\theta]{y_t \mid \yv_{<t}, \xv}\tag{1}\] where \(\yv_{<t} := [y_1, \dots, y_{t-1}]\) and the probability of each token is computed as \(\prob[\theta]{y_t \mid \yv_{<t}, \xv} := \mathrm{softmax}(\hv_{t-1} \Wv)\). Note that the ordering of tokens in Eq. 1 can be arbitrary, but most language models typically use a fixed left-to-right order. To train the model, we can maximize the (conditional) log-likelihood \(\sum_{(\yv, \xv) \in D} \log \prob[\theta]{\yv \mid \xv}\) on the training data.
Language models are typically represented with recurrent neural architectures bengio2003neural?. Specifically, modern large-scale models, including GPT-2 radford2018improving? used in our work, are based on the transformers vaswani2017attention?. The models are usually pretrained on large unsupervised corpora crawled from the web radford2019language? and then fine-tuned to specific domains or tasks.
Decoding. To generate text, we need to be able to decode sequences of tokens from the distribution represented by a language model. The most commonly used approach in non-open-domain generation is beam search vijayakumar2016diverse? that produces sequences by approximately maximizing the likelihood under the learned model. It has been shown that maximization-based decoding in open-domain generation often leads to degenerate text samples (very unnatural and extremely repetitive text holtzman2019curious?), and thus sequential sampling approaches are typically used.
Due to heavy tail conditional distributions \(\prob[\theta]{y \mid \yv_{<t}, \xv}\), sequential sampling can be unstable (, a single unlikely word may derail the rest of the sequence); hence in practice, conditional distributions are truncated before sampling either to the top-\(k\) tokens fan2018hierarchical?, radford2019language? or top-\(p\) probability mass holtzman2019curious?. In this work, we use the latter, also called nucleus sampling, and sequentially sample \(y_t\)’s from \(\prob[\theta]{y \mid \yv_{<t}, \xv}\) truncated to the top tokens that contain a total of \(p\) probability mass.
Sequence-to-sequence models. A common approach to conditioning language models on input sequences is the encoder-decoder architecture sutskever2014sequence? supplemented with the attention mechanism bahdanau2014neural?. The architecture represents \(\prob[\theta]{\yv \mid \xv}\) as follows: \[\label{eq:encoder-decoder-model} \prob[\theta]{\yv \mid \xv} := \prob[\theta]{\yv \mid \uv = f_{\theta}(\xv)},\tag{2}\] where \(f_\theta(\cdot)\) is a deterministic encoder that transforms input sequences into intermediate representations \(\uv\) that are used by the language model \(\prob[\theta]{\yv \mid \uv}\) as additional inputs at decoding time. Lewis et al. lewis2019bart? recently proposed BART that uses a BERT-like encoder and a GPT2-like decoder, and is particularly effective when fine-tuned for domain-specific generation. We selected to use BART as a component in ProGeT.

Figure 2: Progressive generation of long text \(\yv\) given any condition \(\xv\). Each stage refines the results from the previous stage by adding finer-grained details. Added content at each stage is highlighted in different colors.
4 Progressive Generation of Text↩︎
One of the main challenges in generating long coherent passages is modeling long-range dependencies across the entire sequences (1000s of tokens). We propose a progressive generation approach that is conceptually simple yet effective. Intuitively, progressive generation divides the complex problem of generating the full passage into a series of much easier steps of generating coarser-grained intermediate sequences. Contrary to generating everything from left to right from scratch, our progressive generation allows the model to first plan globally and then shift attention to increasingly finer details, which results in more coherent text. Figure 2 illustrates the generation process.
The key advantages of our approach include (1) enabling seamless use of powerful pretrained monotonic (left-to-right) LMs in the process of progressive generation which is conceptually non-monotonic (Sec 4.1); (2) Straightforward training of models at each stage in parallel with independent data from domain corpus (Sec 4.2).
4.1 Generation Process↩︎
Instead of generating the full passage \(\yv\) directly, we propose to add multiple intermediate stages: \(\xv \rightarrow \cv_1 \rightarrow \cv_2 \cdots \rightarrow \cv_{K} \rightarrow \yv\), where for each stage \(k\in\{1,\dots,K\}\), \(\cv_k\) is an intermediate sequence containing information of the passage at certain granularity. For instance, at the first stage, \(\cv_1\) can be seen as a highest-level content plan consisting of the most informative tokens such as key entities. Then, based on the plan, we gradually refine them into subsequent \(\cv_k\), each of which contains finer-grained information than that of the preceding stage. At the final stage, we refine \(\cv_K\) into the full passage by adding the least informative words (e.g., stop words). The generation process corresponds to a decomposition of the conditional probability as: \[\begin{align} \small \prob{\yv, \{\cv_k\} | \xv} = \prob{\cv_1|\xv} \Pi_{k=2}^K \prob{\cv_k|\cv_{k-1}, \xv} \prob{\yv |\cv_{K}, \xv}. \end{align}\] As the above intuition, \(\cv_k\) at early stages as the high-level content plans should contain informative or important words, to serve as skeletons for subsequent enrichment.
We next concretely define the order of generation, namely, which words should each stage generates. Specifically, we propose a simple method that constructs a vocabulary \(\mathcal{V}_k\) for each stage \(k\), based on the importance of words in the target domain. Each particular stage \(k\) only produces tokens belonging to its vocabulary \(\mathcal{V}_k\). By the progressive nature of the generation process, we have \(\mathcal{V}_1\subset \cdots\subset \mathcal{V}_K\subset \mathcal{V}\). That is, \(\mathcal{V}_1\) contains the smallest core set of words in the domain, and the vocabularies gradually expand at later stages until arriving the full vocabulary \(\mathcal{V}\). We discuss the construction of the vocabularies in the below.
4.1.0.1 Stage-wise vocabularies based on word importance.
Given a text corpus \(\mathcal{D}\) of the target domain with the full vocabulary \(\mathcal{V}\), we define the importance scores of words in \(\mathcal{V}\) based on the TF-IDF metric. We then rank all the words and assign the top \(V_k\) words to the intermediate vocabulary \(\mathcal{V}_k\). Here \(V_k\) is a hyper-parameter controlling the size of \(\mathcal{V}_k\).
More concretely, for each word \(w\in\mathcal{V}\), we first compute its standard TF-IDF score salton1986introduction? in each document \(\dv\in\mathcal{D}\), which essentially measures how important \(w\) is to \(\dv\). The importance of the word \(w\) in the domain is then defined as the average TF-IDF score across all documents containing \(w\): \[\small \label{eq:term-importance} \mathrm{importance}(w, \mathcal{D}) = \frac{\sum_{\dv \in \mathcal{D}} \mathrm{TF\_IDF}(w, \dv)}{\mathrm{DF}(w, \mathcal{D})},\tag{3}\] where \(\mathrm{TF\_IDF}(w, \dv)\) is the TF-IDF score of word \(w\) in document \(\dv\); and \(\mathrm{DF}(w, \mathcal{D})\) is the document frequency, , the number of documents in the corpus that contain the word \(w\).

Figure 3: Training for Progressive Generation of Long Text
4.1.0.2 Pretrained language models as building blocks.
A key advantage of our design of the progressive generation process is the compatibility with the powerful pretrained LMs that perform left-to-right generation. Specifically, although our approach implements a non-monotonic generation process that produces importance words first, we can generate intermediate sequences \(\cv_k\) at each stage in a left-to-right manner. Thus, we can plug pretrained LM, such as GPT-2 or BART, into each stage to carry out the generation. As described more in section 4.2, for each stage \(k\), we can conveniently construct stage-specific training data from the domain corpus \(\mathcal{D}\) using the stage-wise vocabulary \(\mathcal{V}_k\), and fine-tune the stage-\(k\) LM in order to generate intermediate sequences at the stage that are pertaining to the target domain.
One can add masks on the pretrained LM’s token distributions to ensure the LM only produces tokens belonging to \(\mathcal{V}_k\). In practice, we found it is not necessary, as the pretrained LM can usually quickly learns the pattern through fine-tuning and generate appropriate tokens during inference. In our experiments (section 5), we use BART for all \(k>1\) stages, since BART is an encoder-decoder model which can conveniently take as inputs the resulting sequence from the preceding stage and generate new. For the first stage, we use GPT-2 for unconditional generation tasks, and BART for conditional generation. We note that GPT-2, and other relevant pretraiened LMs, can indeed also be used as a conditional generator radford2019language?, liu2018generating? and thus be plugged into any of stages.
4.2 Training↩︎
Our approach permits straightforward training/fine-tuning of the (pretrained) LMs at different stages given the domain corpus \(\mathcal{D}\). In particular, we can easily construct independent training data for each stage, and train all LMs in parallel.
More concretely, for each stage \(k\), we use the stage vocabularies \(\mathcal{V}_{k-1}\) and \(\mathcal{V}_k\) to filter all relevant tokens in the documents as training data. That is, given a document, we extract the sub-sequence \(\cv_{k-1}^*\) of all tokens from the document that are belonging to \(\mathcal{V}_{k-1}\), and similarly extract sub-sequence \(\cv_{k}^*\) belonging to \(\mathcal{V}_{k}\). The \(\cv_{k-1}^*\) and \(\mathcal{V}_{k}\) are then used as the input and the ground-truth output, respectively, for training the LM at stage \(k\) with maximum likelihood learning. Therefore, given the stage-wise vocabularies \(\{\mathcal{V}_k\}\), we can automatically extract training data from the domain corpus \(\mathcal{D}\) for different stages, and train the LMs separately.
Stage-level exposure bias and data noising. In the above training process, the outputs of each LM are conditioning on the ground-truth input sequences extracted from the real corpus. In contrast, at generation time, the LM takes as inputs the imperfect sequences produced at the previous stage, which can result in new mistakes in the outputs since the LM has never be exposed to noisy inputs during training. Thus, the discrepancy between training and generation can lead to mistakes in generation accumulating through the stages. The phenomenon resembles the exposure bias issue ranzato2015sequence? of sequential generation models at token level, where the model is trained to predict the next token given the previous ground-truth tokens, while at generation time tokens generated by the model itself are instead used to make the next prediction.
To alleviate the issue and increase the robustness of each intermediate LM, we draw on the rich literature of addressing token-level exposure bias xie2017data?, tan2018connecting?. Specifically, during training, we inject noise into the ground-truth inputs at each stage by randomly picking an \(n\)-gram (\(n\in\{1,2,3,4\}\)) and replacing it with another randomly sampled \(n\)-gram. The data noising encourages the LMs to learn to recover from the mistakes in inputs, leading to a more robust system during generation.
5 Experiments↩︎
5.1 Setup↩︎
5.1.0.1 Domains.
We evaluate on two text generation domains including: (1) CNN News hermann2015teaching? for unconditional generation. It includes about 90K documents and we randomly sample 5K for each of dev and test sets.; (2) WritingPrompts fan2018hierarchical? for conditional story generation. The task is to generate a story given a prompt. This dataset has 272K/15K/15K examples in train/dev/test set.
5.1.0.2 Model configs.
In the CNN News domain, we use GPT2-Large as the first-stage model and use BARTs for the rest of stages, and in the story domain, we use BARTs for all stages. Due to computation limitations, we experiment models with 2-stage and 3-stage generations. In our 2-stage model, our first stage covers about 30% of all content, and in our 3-stage model, the first and second stages cover 20% and 30% of all content respectively. For model training, we follow the same protocol as see2019massively? to fine-tune all pretrained models until convergence. In the generation phase, we use the top-p decoding strategy proposed by holtzman2019curious? with \(p=0.95\) to generate 1024 tokens at maximum. Refer to our supplementary for more details.
5.1.0.3 Evaluation metrics.
We use combinations of automatic metrics and human evaluations to evaluate the domain-specific quality of text generated by GPT-2, BART and our progressive method.
0pt
MS-Jaccard (MSJ). Proposed by montahaei2019jointly?, MS-Jaccard metric measures the similarity of the n-grams frequencies between two sets of texts with Jaccard index. For 2,3,4,5-grams, we report MSJ2,3,4,5 respectively. Under this metric, the higher, the better.
Fréchet BERT Distance (FBD) Proposed by montahaei2019jointly?, Fréchet BERT Distance (FBD) is similar to the Fréchet Inception Distance (FID) metric in computer vision tasks, and it uses BERT as a feature provider. We compute the distance with features from every layer of BERT-large, and report the sums of layers 1-8, 9-16, 17-24 and call them FBD-S (shallow), FBD-M (medium), FBD-D (deep) respectively. Under this metric, the lower, the better.
TF-IDF Feature Distance (TID) We propose a simple but intuitive metric. A traditional way to classify texts is based on the TF-IDF feature, so we use the distance between the average TF-IDF features of two passage sets to indicate their distance. Under this metric, the lower, the better.
Harmonic BLEU Defined by shi2018toward?, harmonic BLEU is the F1 score of Forward and Backword BLEUs. Here we use harmonic BLEU as a metric of domain-specific quality and backward BLEU as a metric of diversity.
Human Evaluation. We also conduct human evaluation. Human annotators are asked to rate each generated sample in terms of coherence with 5-Likert scale.
| News (CNN) | Story (WritingPrompts) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Metric | BART | GPT2-S | GPT2-L | ProGeT-2 | ProGeT-3 | BART | GPT2-S | GPT2-L | ProGeT-2 | ProGeT-3 | |
| BLEU2\(_H\uparrow\) | 84.99 | 84.57 | 84.92 | 85.21 | 85.31 | 87.00 | 86.49 | 86.25 | 87.85 | 87.56 | |
| BLEU3\(_H\uparrow\) | 65.28 | 64.03 | 64.81 | 65.39 | 65.71 | 70.05 | 68.45 | 68.28 | 70.75 | 70.66 | |
| BLEU4\(_H\uparrow\) | 44.58 | 42.92 | 43.89 | 44.54 | 44.94 | 49.59 | 47.12 | 47.15 | 49.94 | 50.12 | |
| BELU5\(_H\uparrow\) | 28.41 | 26.81 | 27.76 | 28.28 | 28.63 | 31.43 | 28.80 | 29.00 | 31.43 | 31.75 | |
| MSJ2 \(\uparrow\) | 60.81 | 61.72 | 60.10 | 61.73 | 61.43 | 64.68 | 67.03 | 63.37 | 66.08 | 65.07 | |
| MSJ3 \(\uparrow\) | 40.47 | 40.38 | 39.87 | 41.13 | 41.13 | 46.22 | 46.59 | 44.15 | 47.20 | 46.69 | |
| MSJ4 \(\uparrow\) | 24.89 | 24.30 | 24.36 | 25.27 | 25.38 | 29.93 | 29.21 | 27.84 | 30.52 | 30.37 | |
| MSJ5 \(\uparrow\) | 14.77 | 14.09 | 14.36 | 15.00 | 15.11 | 18.13 | 17.05 | 16.38 | 18.40 | 18.42 | |
| FBD-S \(\downarrow\) | 6.71 | 6.64 | 6.55 | 6.53 | 6.44 | 3.80 | 2.92 | 3.50 | 2.35 | 2.78 | |
| FBD-M \(\downarrow\) | 17.68 | 15.92 | 13.51 | 14.07 | 12.97 | 17.16 | 14.25 | 14.88 | 13.40 | 13.87 | |
| FBD-D \(\downarrow\) | 36.16 | 34.25 | 26.94 | 27.69 | 24.62 | 36.02 | 30.59 | 31.05 | 27.32 | 28.31 | |
| TID \(\downarrow\) | 7.49 | 8.20 | 7.05 | 6.38 | 5.88 | 3.09 | 3.08 | 3.92 | 2.33 | 2.37 | |
5.2 Results↩︎
Table 1 shows the results of our progressive model on both CNN News and story domain measured in BLEU, MSJ, FBD and TID against test set. Our progressive models outperform baseline models on overwhelmingly most of the metrics, which indicates our models generate much more similar text to human. Moreover, the improvement is consistent both on unconditional generation (CNN) and conditional generation (WritingPrompts). It is worth noting that 3-steps model performs better than 2-stages model in the CNN News domain, while in the story generation domain, we don’t observe significantly improved quality by using 3-steps model. This suggests that the influence of the number of progressive steps might be different across different domains.
Besides those metrics, we also measure diversity–an aspect in which we usually observe language model suffers–using backward BLEU in Figure 4. Our models can generate much more diverse text compared with GPT, which could be attributed to global planning with progressive generation.
Besides automatic evaluation, we ask human annotators to evaluate the text generated by different models according to our score standard introduced previously. The scores on text samples are averaged and shown in Table 2 with standard deviations. First, we can see that all models get scores higher than 3, which indicates most of the generated texts from baselines are at least moderately coherence. However, all baseline models have scores of around 3.5 while our progressive model gets a significantly higher score of 4.43, suggesting our samples are much harder to distinguish with human text.
In Figure [fig:sample95efficiency], we study the sample efficiency of different models by varying the amount of training data. We can see that the advantage of our model is more prominent when the data size is decreased. Our model can make more efficient use the training data in learning to generate high quality samples.
Figure 4: 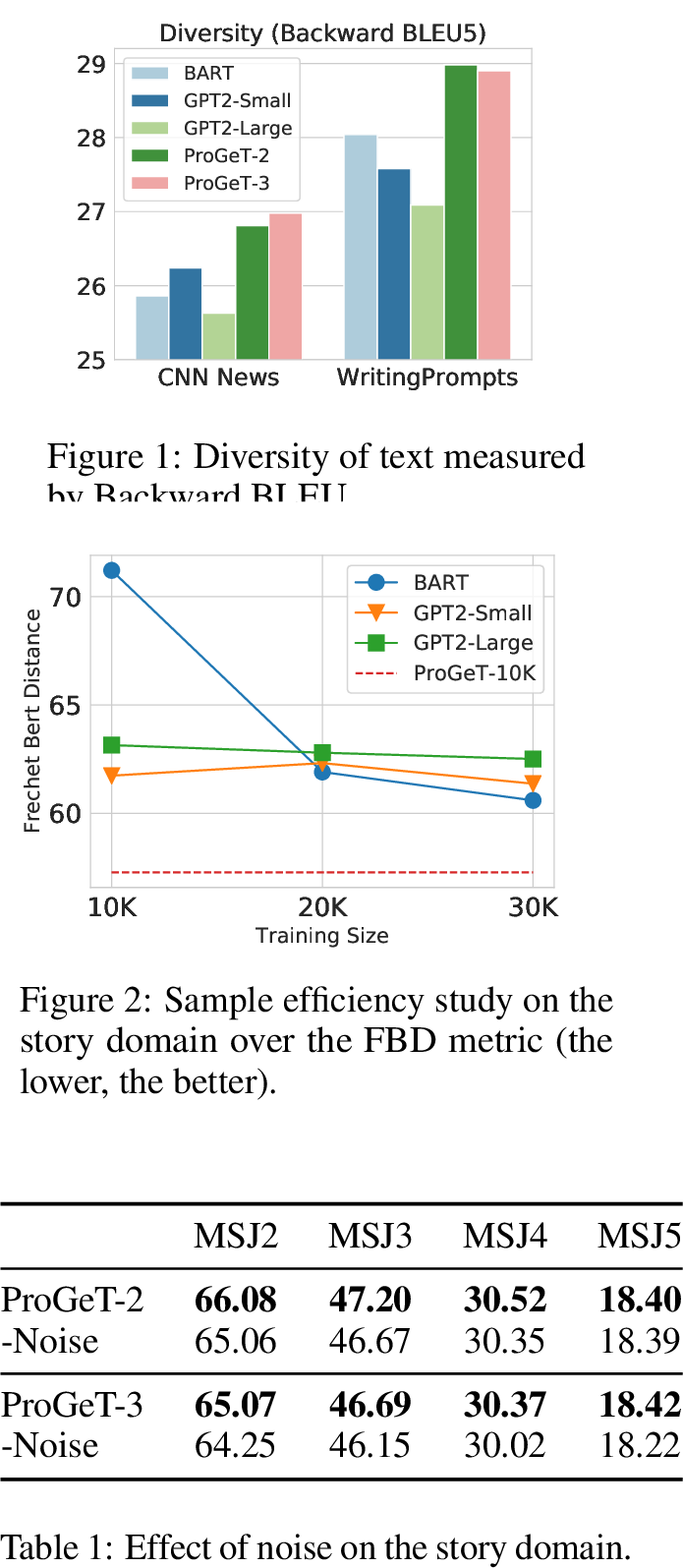 .
.
5.3 Ablation Study↩︎
5.3.0.1 Effect of Data Noising
We try the ablation of data noising, to check whether the noise operation really helps reduce stage-wise exposure bias (Sec 4.2) as we expected. Table [tab:noise] shows the comparison between models with and without noise in training. In both 2- and 3-steps generation, noise brings significant performance improvement onto our progressive model.
5.3.0.2 Generation with Gold Plan
To investigate the importance of dividing the generation process into stages and what the stages learn separately, we add another set of texts into our comparison. It is a 2-stages model whose first stage is the ground truth (gold plan) while the second stage kept the same (a BART model), shown as GoldPlan in Table 3. Note that with gold plan, our model greatly decreases the gap with human text in MSJ and FBD metrics, which amplifies the importance of plans in text generation. The intermediate plans are information bottleneck and high quality plans indicate high quality text generation.
| BART | GPT2-S | GPT2-L | Ours | |
|---|---|---|---|---|
| Human | 3.17 \(\pm\) 0.99 | 3.61 \(\pm\) 1.26 | 3.51 \(\pm\) 1.43 | 4.43 \(\pm\) 0.48 |
| MSJ4 | FBD-D | |||||
|---|---|---|---|---|---|---|
| ProGeT-2 | 25.27 | 27.69 | ||||
| GoldPlan | 27.37 | 16.40 | ||||
| Human (Dev Set) | 28.34 | 11.64 |
First Stage: beckham \n liverpool bayern chelsea \n beckham chelsea mancini \n liverpool \n club [...] |
|
Second Stage: beckham newcastle \n footballer acquisition transfer liverpool bayern munich chelsea munich \n beckham chelsea season italian siro gianluigi mancini season italy
\n season liverpool season \n wembley club \n [...] |
|
| Final Stage: | |
(CNN) – England striker Ashley Beckham has joined Premier League strugglers Newcastle United. \n England Football Association chairman Stephen McClaren confirmed the acquisition of the 20-year-old England
international on Wednesday, making the move official following a lucrative transfer agreement with Liverpool, Munich and Chelsea.\n Beckham spent the first half of this year on loan at Chelsea and did not start a single match during the season
at the Italian capital’s San Siro despite being named the player of the season of the year by Italy. \n However, he played 17 times last season and 12 times this season for Liverpool, making 33 league appearances and scoring seven goals.
\n He is currently third on the all-time England goalscoring list behind only England manager Alex Ferguson and new club teammate Paul Gascoigne. [...] |
5.4 Example generations↩︎
Table 4 shows an example of text generated via three stages. We can see our model first generates the key subject beckham and the team name liverpool in the very first stage, then adds more fine-grained details like acquisition, transfer in the second stage and finally expands the keywords into a full document describing Beckham’s joining a new team.
Our content-first and coarse-to-fine nature of our progressive approach allows for a higher degree over the generated content. Here we show two easy ways to implement basic content controlling and the examples are provided in supplementary materials due to space limit.
Content manipulation via editing intermediate sequences. The first manner is to manipulate the content with an existing intermediate sequence. Specifically, we can replace some words in the input sequences. In this case, the content of generated text can be desired manipulated with other content being similar as before, together with coherence and rationality.
Controlling the content via prefixes. The second manner to control content is writing a prefix for the sketch and using the first-step model to complete it, then the content should be closely related to the prefix words you write.
6 Conclusion↩︎
In this work we have proposed a new approach for domain-specific generation of long text passages in a progressive manner. Our method is simple and efficient and is fully based on fine-tuning large-scale off-the-shelf language and sequence-to-sequence models. We demonstrate that our method outperforms GPT-2—one of the most recent and competitive state-of-the-art story generation methods—in terms domain-specific quality and diversity of the produced samples as measured by a variety of metrics.